

目录
快速导航-

综述评论 | 基于视觉的相机位姿估计方法综述
综述评论 | 基于视觉的相机位姿估计方法综述
-

综述评论 | 3D场景渲染技术
综述评论 | 3D场景渲染技术
-
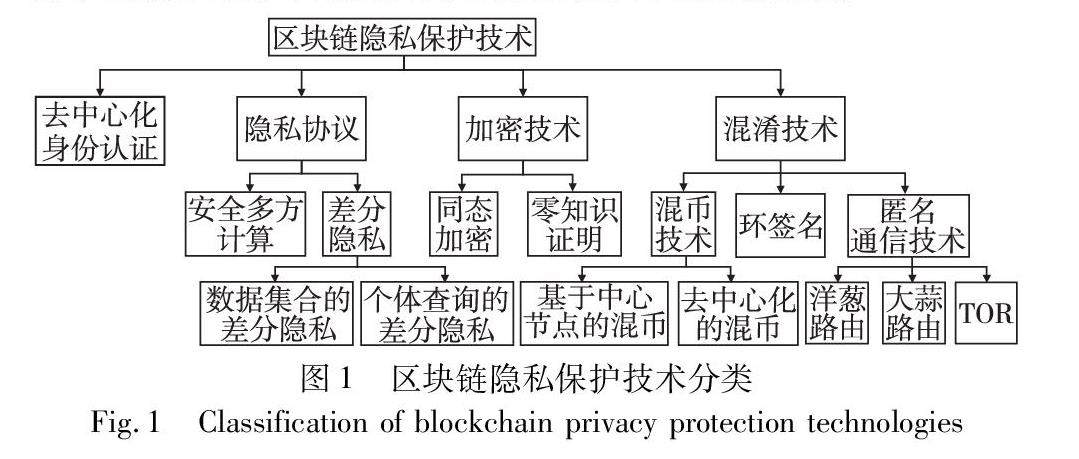
综述评论 | 区块链隐私保护技术研究综述
综述评论 | 区块链隐私保护技术研究综述
-
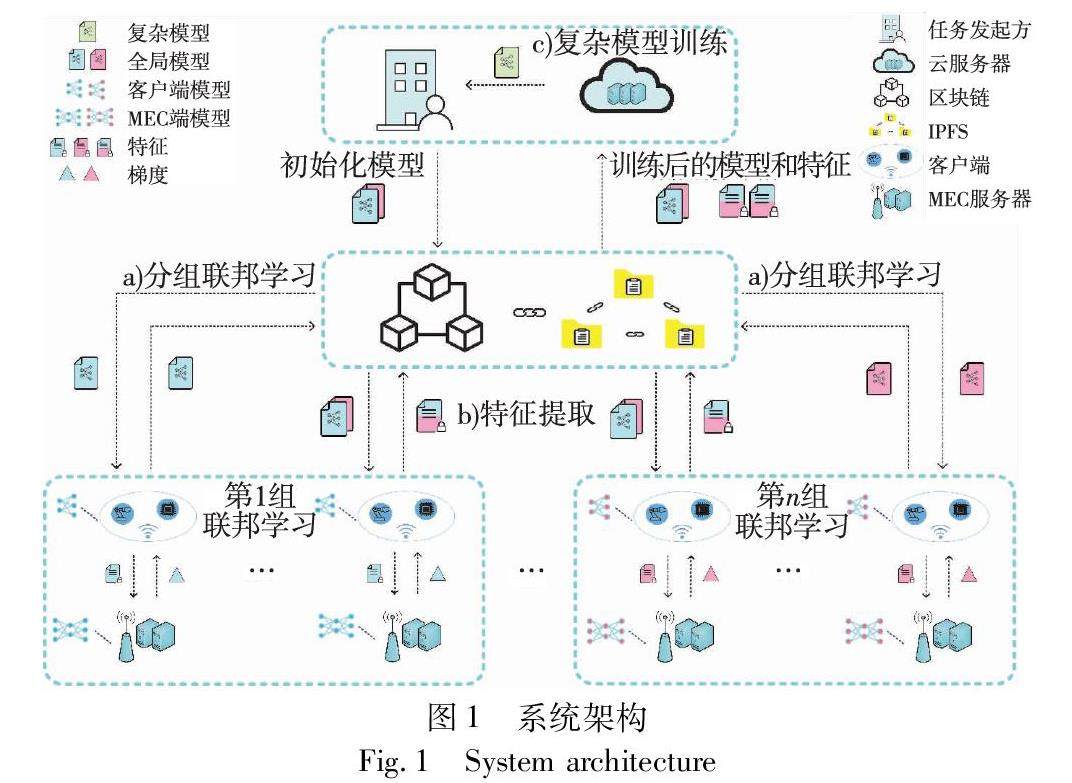
区块链技术 | 基于区块链的工业物联网隐私保护协作学习系统
区块链技术 | 基于区块链的工业物联网隐私保护协作学习系统
-
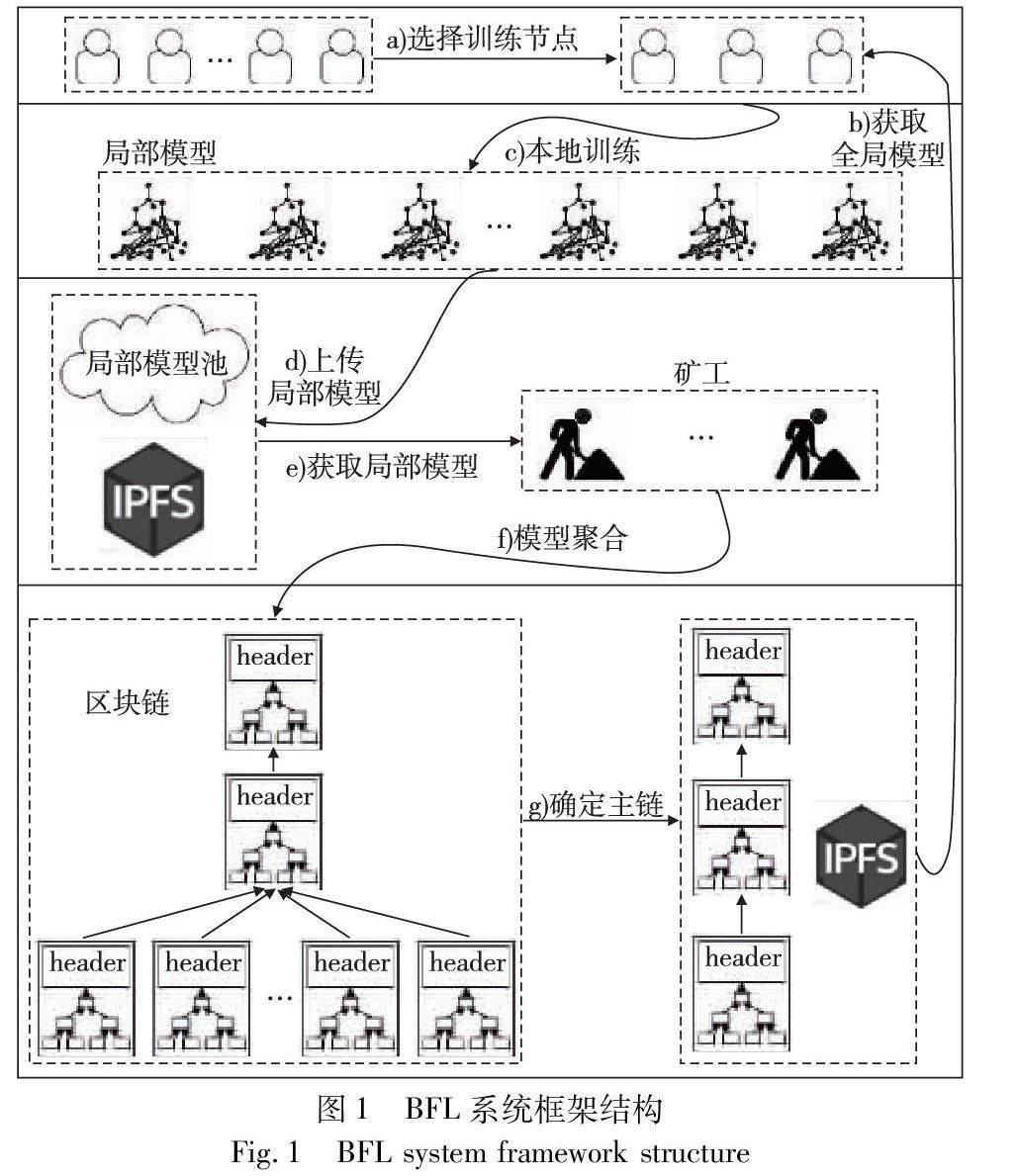
区块链技术 | 基于区块链的联邦学习模型聚合方案
区块链技术 | 基于区块链的联邦学习模型聚合方案
-
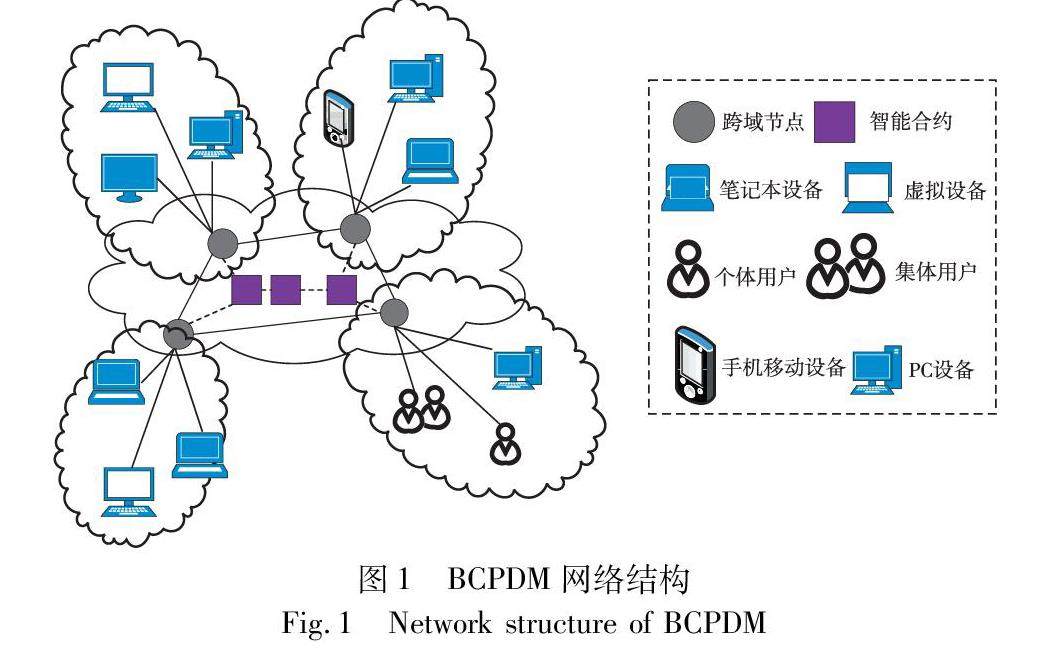
区块链技术 | 基于区块链的汽车产业链权限委托方法
区块链技术 | 基于区块链的汽车产业链权限委托方法
-

数据挖掘专题 | 基于最大联盟粗糙集的三支聚类
数据挖掘专题 | 基于最大联盟粗糙集的三支聚类
-

数据挖掘专题 | 一种有效的周期高效用序列模式增量挖掘算法
数据挖掘专题 | 一种有效的周期高效用序列模式增量挖掘算法
-
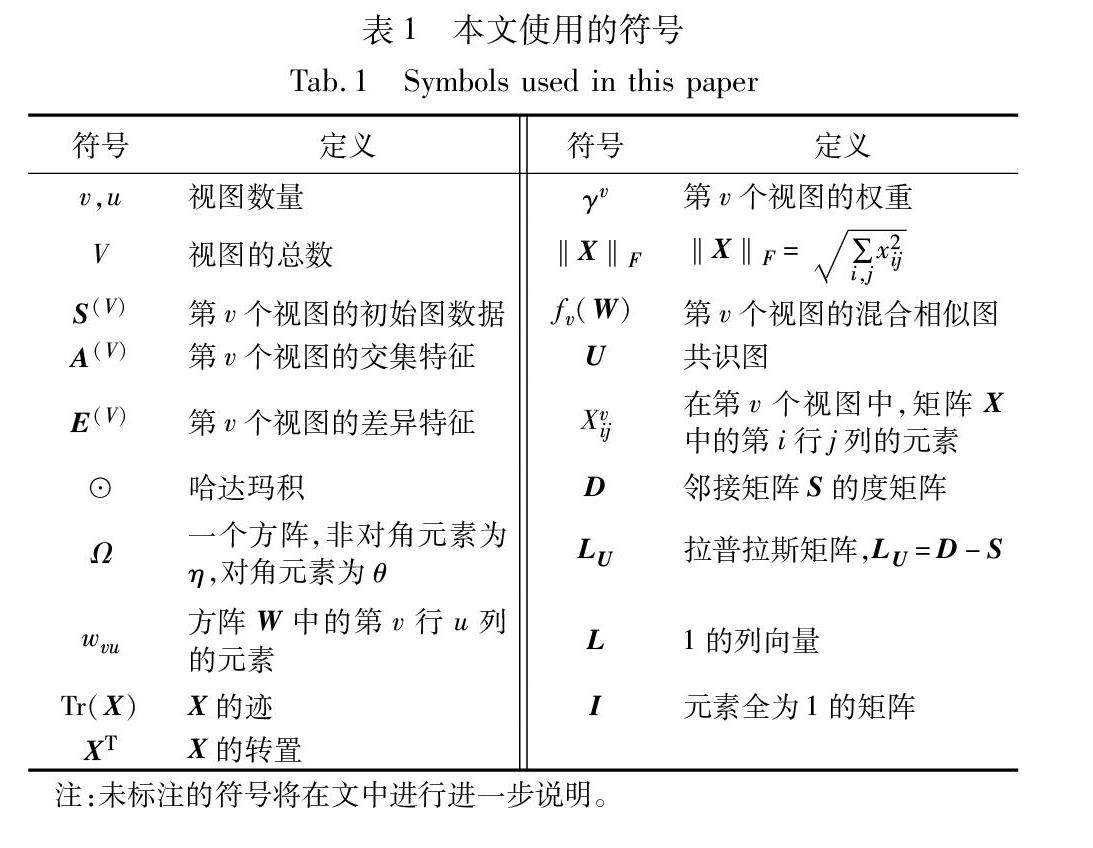
数据挖掘专题 | 多样性约束和高阶信息挖掘的多视图聚类
数据挖掘专题 | 多样性约束和高阶信息挖掘的多视图聚类
-

算法研究探讨 | 基于Transformer交互指导的医患对话联合信息抽取方法
算法研究探讨 | 基于Transformer交互指导的医患对话联合信息抽取方法
-

算法研究探讨 | 融合相似度负采样的远程监督命名实体识别方法
算法研究探讨 | 融合相似度负采样的远程监督命名实体识别方法
-
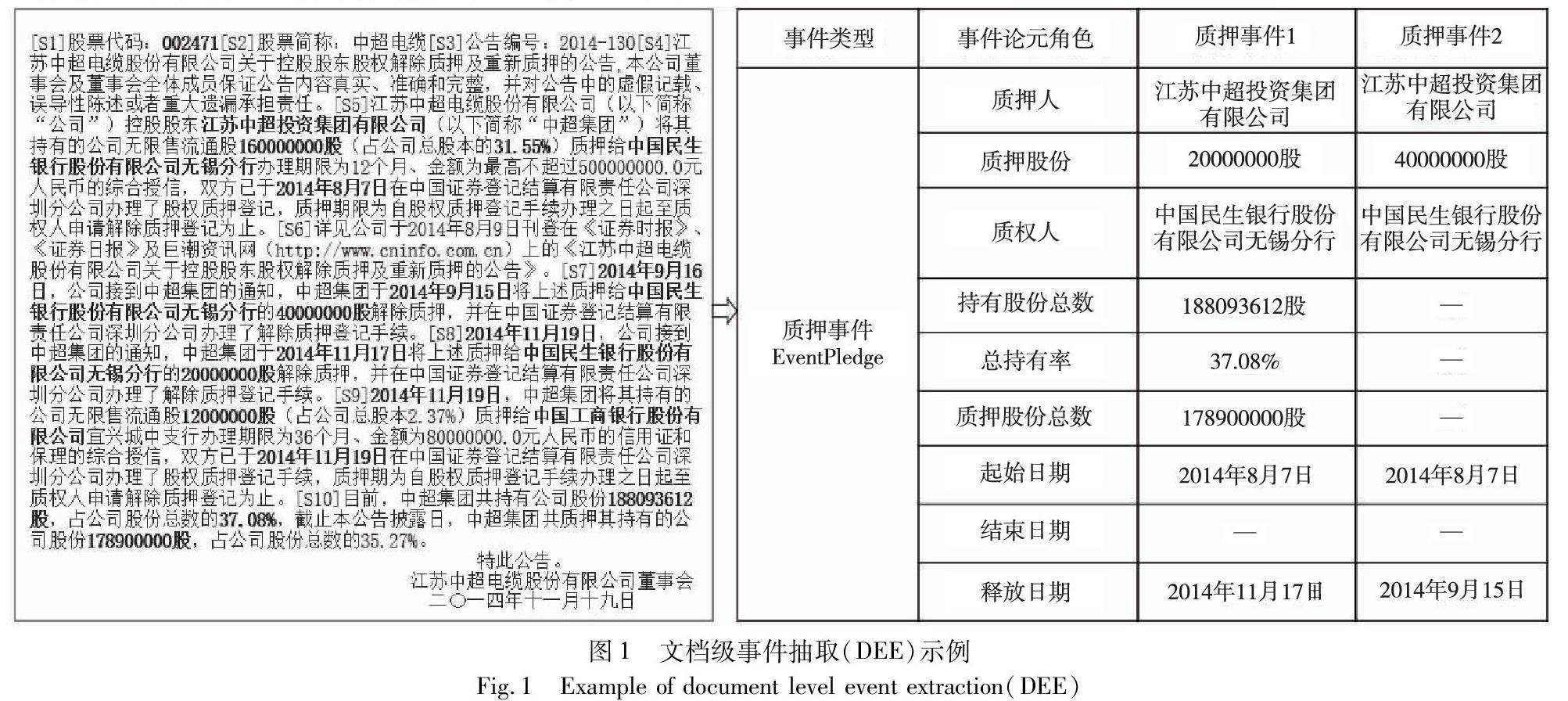
算法研究探讨 | 基于多粒度阅读器和图注意力网络的文档级事件抽取
算法研究探讨 | 基于多粒度阅读器和图注意力网络的文档级事件抽取
-
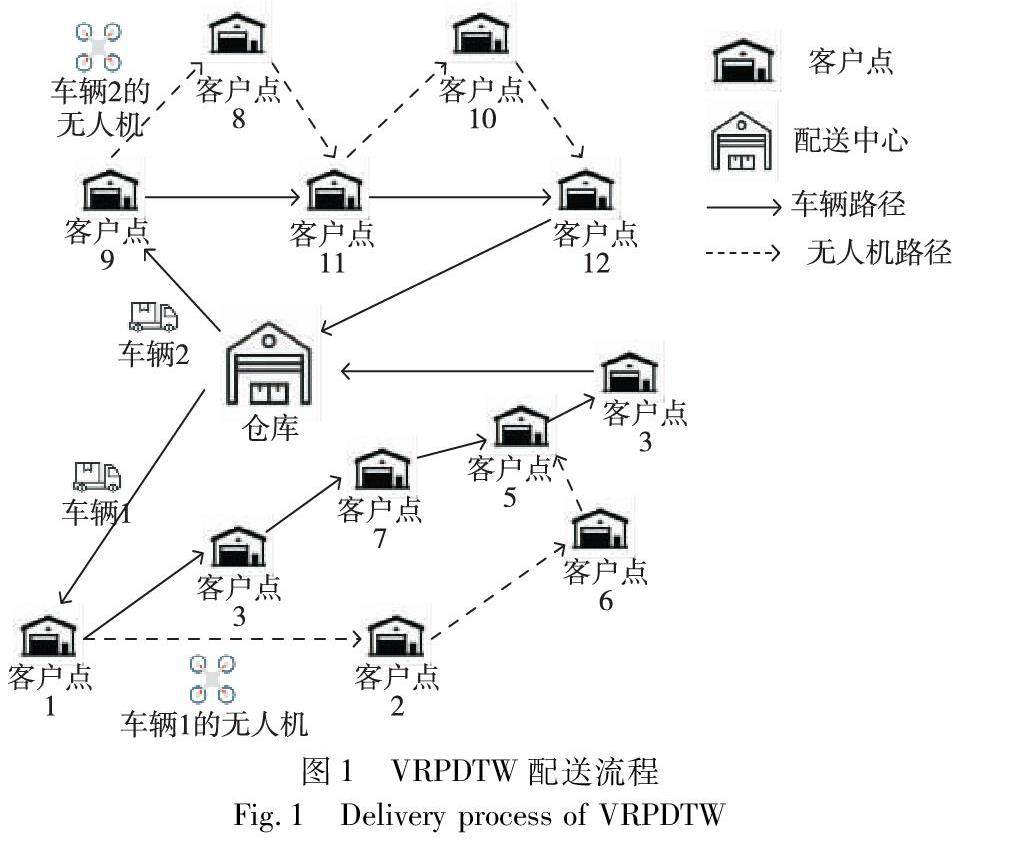
算法研究探讨 | 改进混合粒子群算法求解带时间窗的无人机与车辆协同路径调度问题
算法研究探讨 | 改进混合粒子群算法求解带时间窗的无人机与车辆协同路径调度问题
-
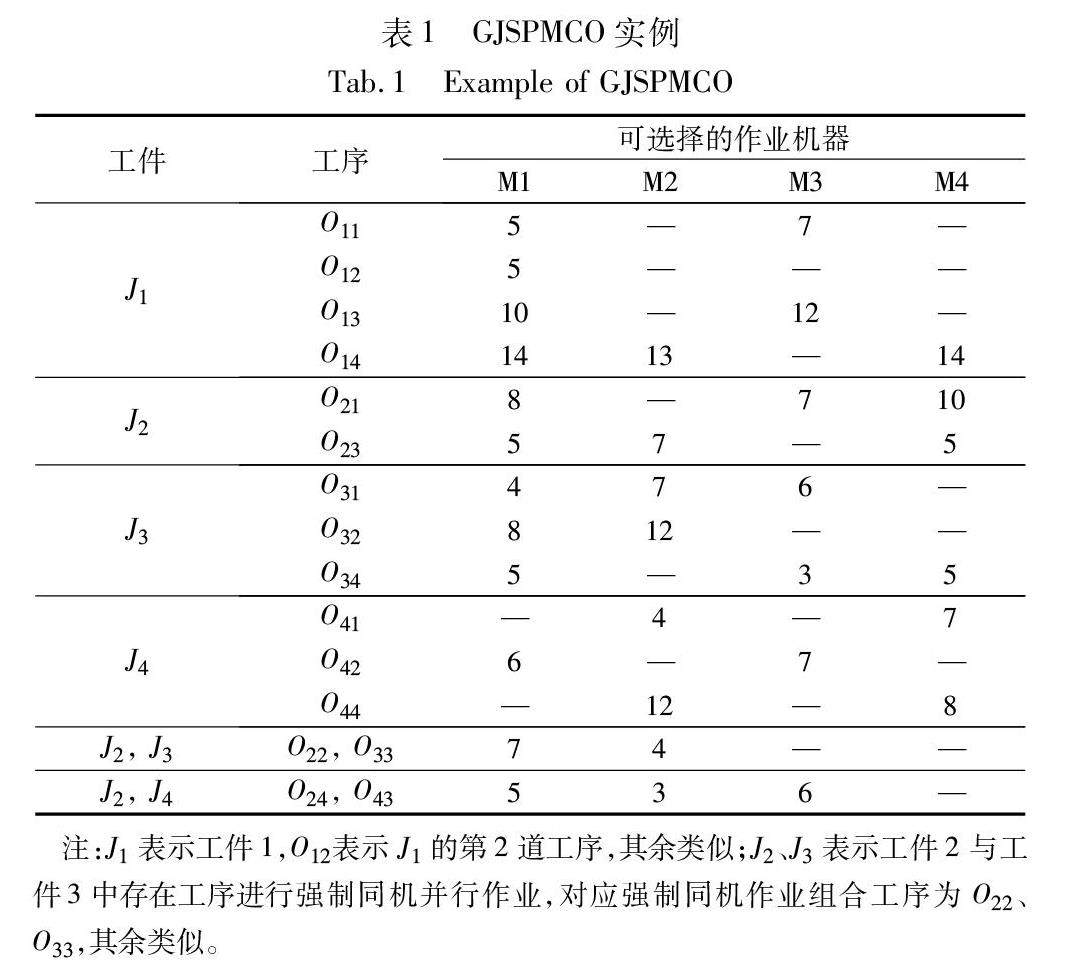
算法研究探讨 | 考虑强制同机并行作业的广义作业车间调度优化
算法研究探讨 | 考虑强制同机并行作业的广义作业车间调度优化
-

算法研究探讨 | 考虑模糊质检时间的柔性作业车间动态调度问题
算法研究探讨 | 考虑模糊质检时间的柔性作业车间动态调度问题
-

算法研究探讨 | 基于自适应平衡静动态联合网络的公交客流预测
算法研究探讨 | 基于自适应平衡静动态联合网络的公交客流预测
-
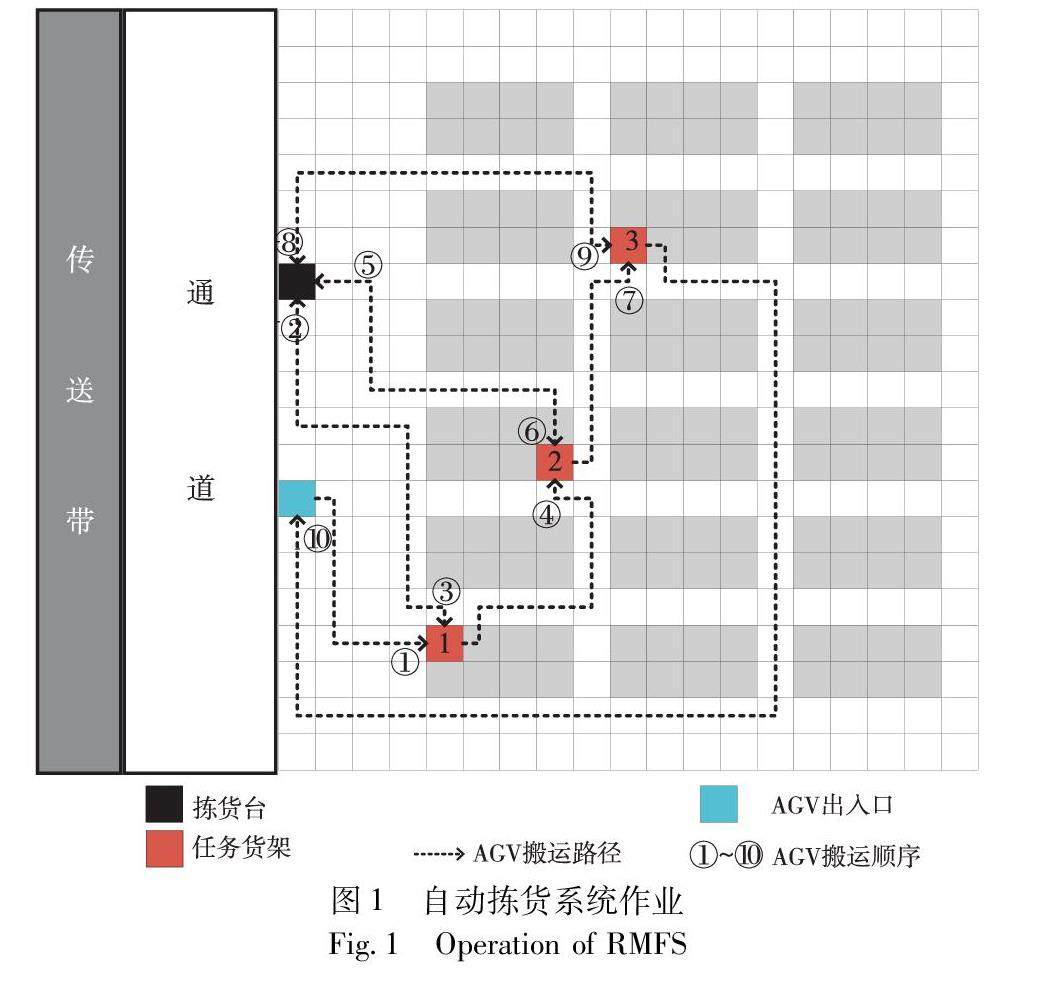
算法研究探讨 | 考虑负载量均衡的自动拣货系统AGV任务分配优化
算法研究探讨 | 考虑负载量均衡的自动拣货系统AGV任务分配优化
-
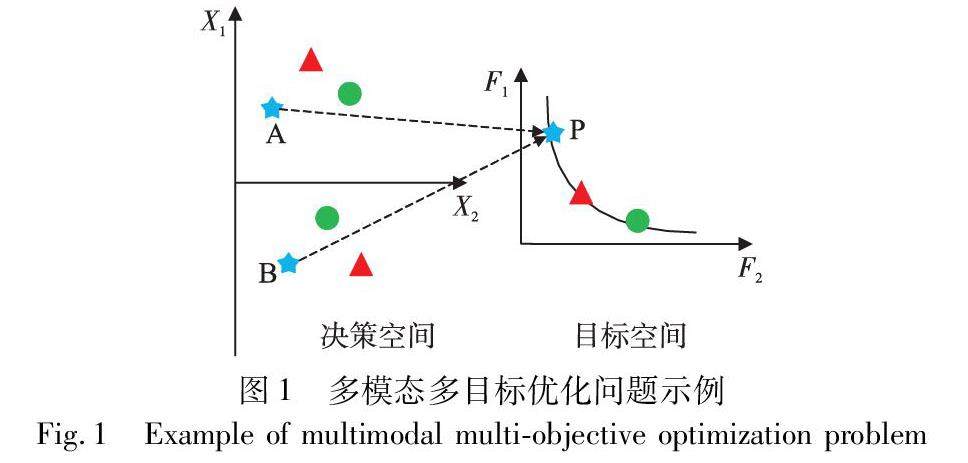
算法研究探讨 | 基于分区搜索和强化学习的多模态多目标头脑风暴优化算法
算法研究探讨 | 基于分区搜索和强化学习的多模态多目标头脑风暴优化算法
-
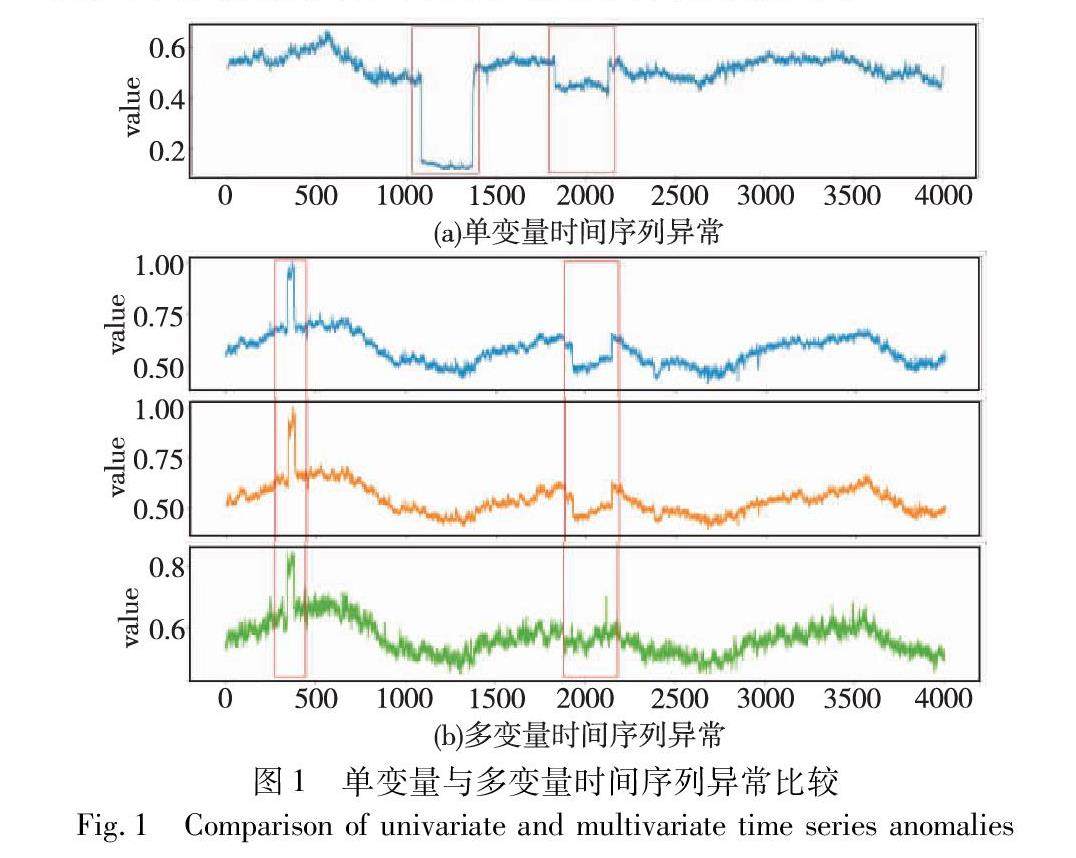
算法研究探讨 | 结合对抗互信息的多变量时间序列抗噪异常检测
算法研究探讨 | 结合对抗互信息的多变量时间序列抗噪异常检测
-

算法研究探讨 | 单源域泛化中一种基于域增强和特征对齐的元学习方案
算法研究探讨 | 单源域泛化中一种基于域增强和特征对齐的元学习方案
-

算法研究探讨 | 基于旋转粒化的逻辑回归算法
算法研究探讨 | 基于旋转粒化的逻辑回归算法
-

算法研究探讨 | 精英引导和信息交互的多目标狼群算法
算法研究探讨 | 精英引导和信息交互的多目标狼群算法
-
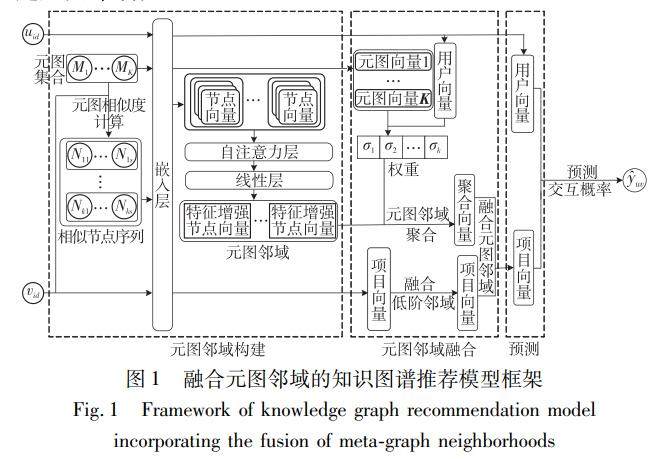
算法研究探讨 | 融合元图邻域的知识图谱推荐模型
算法研究探讨 | 融合元图邻域的知识图谱推荐模型
-
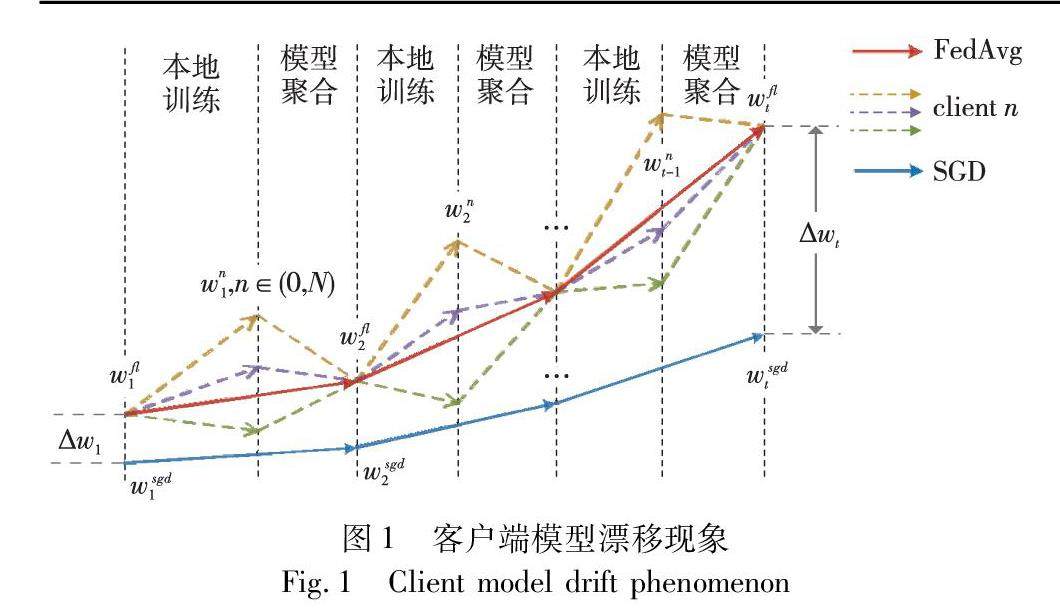
算法研究探讨 | 去中心化场景下的隐私保护联邦学习优化方法
算法研究探讨 | 去中心化场景下的隐私保护联邦学习优化方法
-

算法研究探讨 | 基于模型质量评分的联邦学习聚合算法优化
算法研究探讨 | 基于模型质量评分的联邦学习聚合算法优化
-

系统应用开发 | 基于二阶价值梯度模型强化学习的工业过程控制方法
系统应用开发 | 基于二阶价值梯度模型强化学习的工业过程控制方法
-

系统应用开发 | 基于人体骨骼关键点的心血管患者康复训练动作评估方法
系统应用开发 | 基于人体骨骼关键点的心血管患者康复训练动作评估方法
-

系统应用开发 | 基于投资者行为分析的众筹绩效预测模型
系统应用开发 | 基于投资者行为分析的众筹绩效预测模型
-
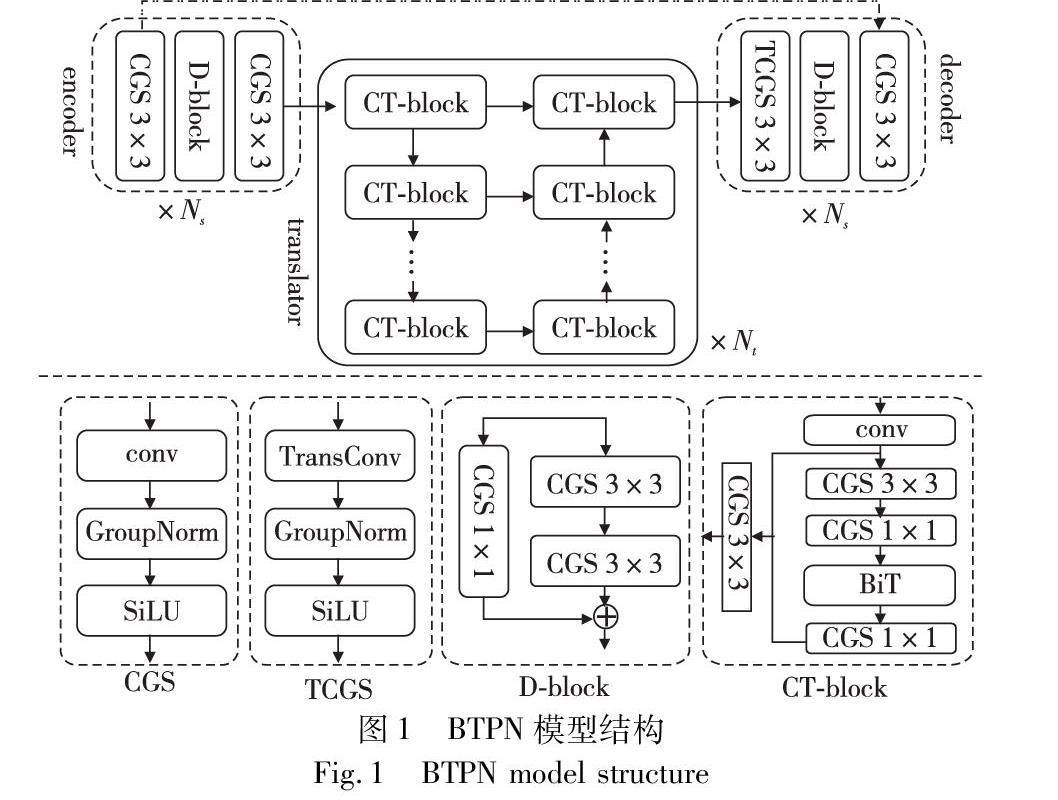
系统应用开发 | 基于双向Transformer的降水临近预报模型
系统应用开发 | 基于双向Transformer的降水临近预报模型
-

软件技术研究 | FMLogs:基于模板匹配的日志解析方法
软件技术研究 | FMLogs:基于模板匹配的日志解析方法
-

软件技术研究 | 基于强化学习选择策略的路径覆盖测试数据生成算法
软件技术研究 | 基于强化学习选择策略的路径覆盖测试数据生成算法
-
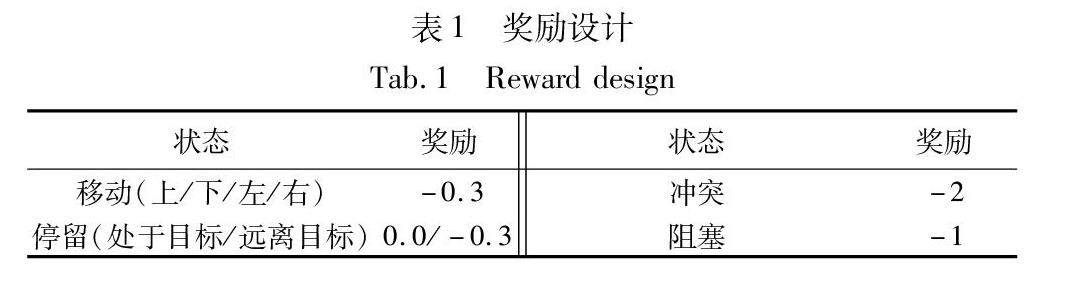
网络与通信技术 | 基于强化和模仿学习的多智能体寻路干扰者鉴别通信机制
网络与通信技术 | 基于强化和模仿学习的多智能体寻路干扰者鉴别通信机制
-
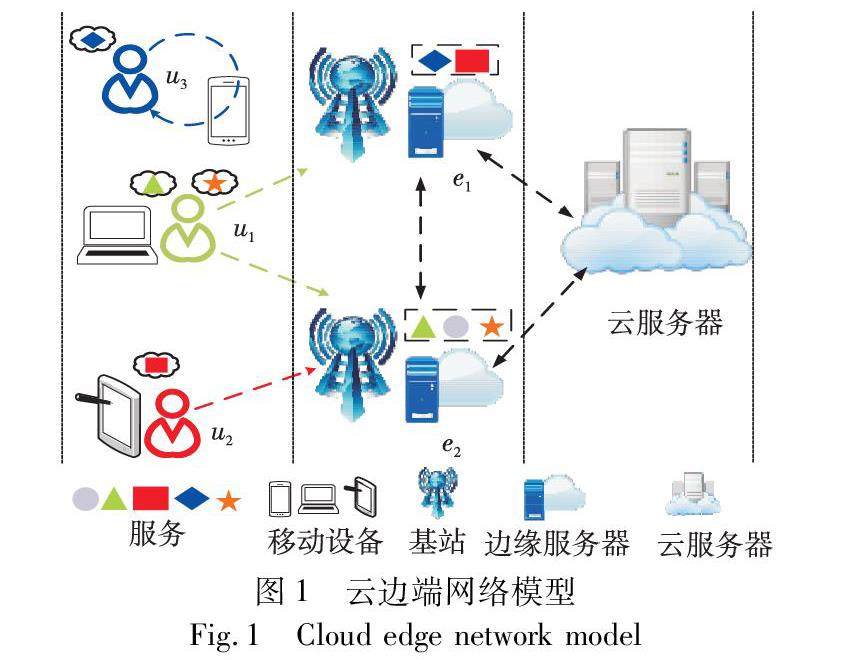
网络与通信技术 | 基于服务更新的异构任务卸载方法
网络与通信技术 | 基于服务更新的异构任务卸载方法
-

网络与通信技术 | 基于CGDNN的低信噪比自动调制识别方法
网络与通信技术 | 基于CGDNN的低信噪比自动调制识别方法
-
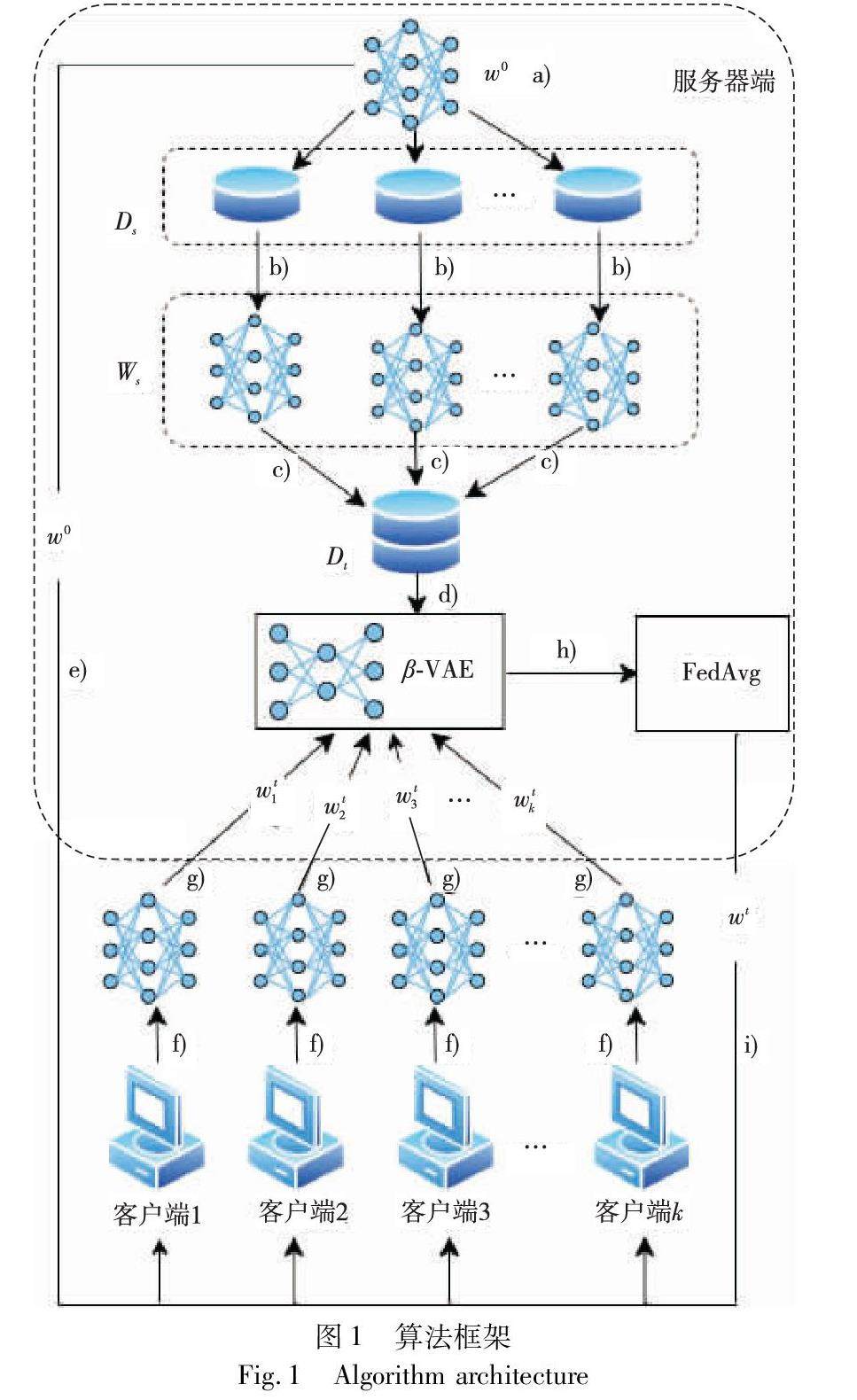
信息安全技术 | 基于β-VAE的联邦学习异常更新检测算法
信息安全技术 | 基于β-VAE的联邦学习异常更新检测算法
-
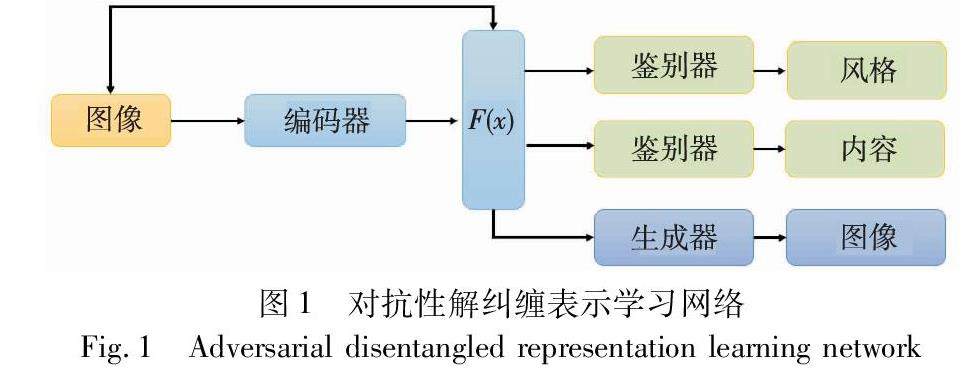
信息安全技术 | 基于解纠缠表示学习的人脸反欺骗算法
信息安全技术 | 基于解纠缠表示学习的人脸反欺骗算法
-

信息安全技术 | 控制失真漂移的HEVC视频自适应隐写算法
信息安全技术 | 控制失真漂移的HEVC视频自适应隐写算法
-

图形图像技术 | 基于多频特征和纹理增强的轻量化图像超分辨率重建
图形图像技术 | 基于多频特征和纹理增强的轻量化图像超分辨率重建
-
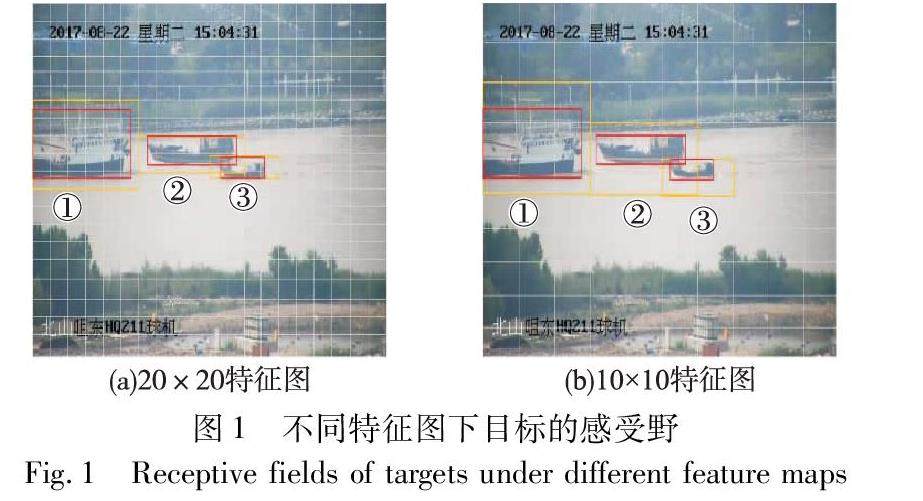
图形图像技术 | 尺度适应性感受野的船舶目标检测方法
图形图像技术 | 尺度适应性感受野的船舶目标检测方法
-
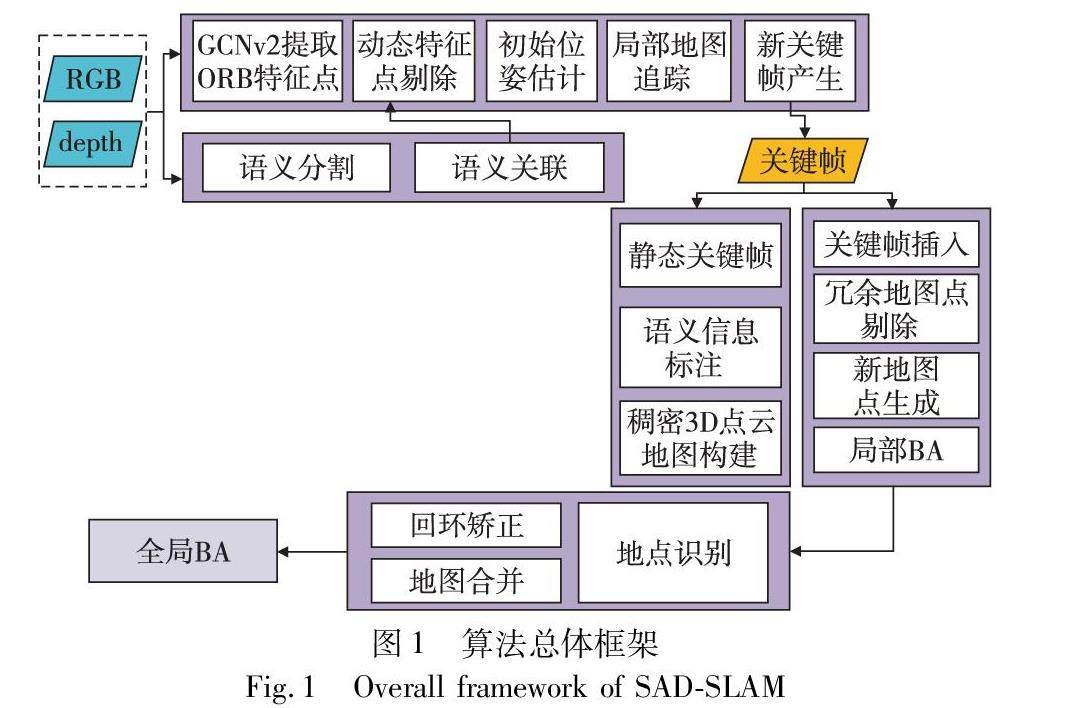
图形图像技术 | 室内动态场景下基于语义关联的视觉SLAM方法
图形图像技术 | 室内动态场景下基于语义关联的视觉SLAM方法
-
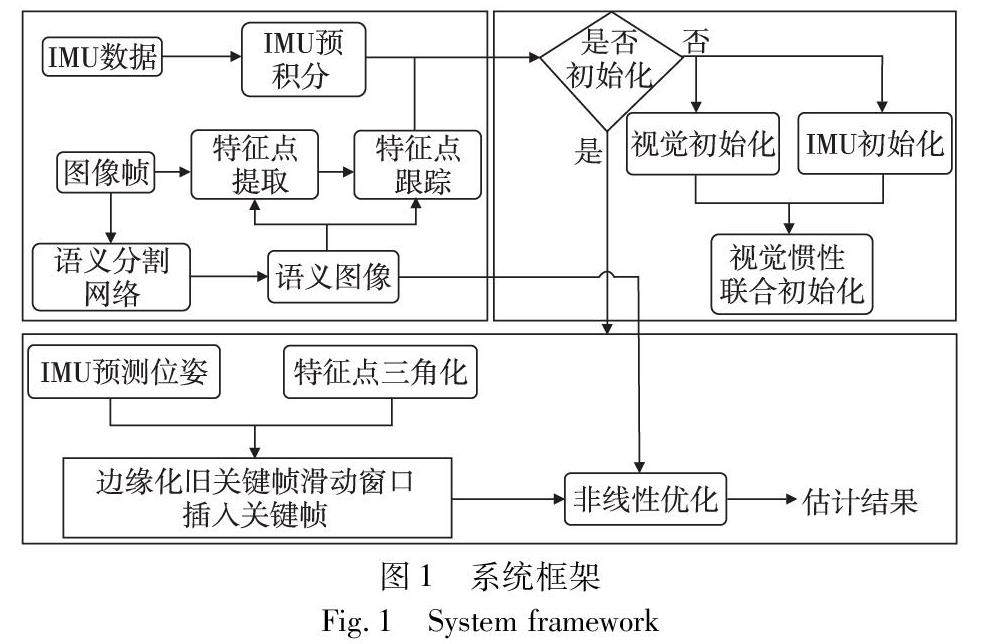
图形图像技术 | 融合语义信息的视觉惯性SLAM算法
图形图像技术 | 融合语义信息的视觉惯性SLAM算法
-

图形图像技术 | 基于深度半监督学习的小样本金属工件表面缺陷分割
图形图像技术 | 基于深度半监督学习的小样本金属工件表面缺陷分割
-

图形图像技术 | 融合多情感的语音驱动虚拟说话人生成方法
图形图像技术 | 融合多情感的语音驱动虚拟说话人生成方法
-

图形图像技术 | 融合CNN和Transformer的并行双分支皮肤病灶图像分割
图形图像技术 | 融合CNN和Transformer的并行双分支皮肤病灶图像分割





















 登录
登录